

Czy Data Lake + Data Warehouse = Lakehouse? Czy będziemy używać podejścia Modern Data Warehouse?
Chciałbym przeprowadzić Cię przez dostępne koncepcje i zastanowić się jak będzie wyglądała przyszłość.
W ostatnim wpisie z serii Od Zera Do Bohatera przyjrzeliśmy się możliwością przechowywania danych nie tylko relacyjnych. Skupiliśmy się na poszczególnych produktach lub usługach. Natomiast, gdy budujemy system przetwarzający dane, to te wszystkie elementy składają się w pewną całość. Dzięki czemu potrafimy nad danymi zapanować.
Wiele z tych koncepcji ma już swoje lata. Napisano na ten temat mnóstwo artykułów i książek. Nie ma sensu odkrywać koła na nowo. Pozwól, że po prostu przeprowadzę Cię przez świat możliwości wraz z linkami do szczegółów.
Ale zacznijmy od początku. Na początku była… baza danych, ale ten etap przeskoczmy i skupmy się na analitycznych rozwiązaniach. Następna była:
Hurtownia Danych (Data Warehouse, w skrócie DWH)
Trudno znaleźć dokładny moment w czasie kiedy zaczęła pojawiać się idea hurtowni danych. Według Wikipedii będą to lata 60-70.

Po latach prób i badań wiemy co było efektem – dwie idee związane z dwoma nazwiskami: Bill Inmon oraz Ralph Kimball.
Jeżeli chcesz dowiedzieć się o nich więcej, wpisz w wyszukiwarce: Kimball vs. Inmon. Znajdziesz tonę artykułów porównujących te podejścia. Przykładowy artykuł znajdziesz tutaj.
Czy te modele to już historia? Nie! Są stosowane do dzisiaj. Może obiły Ci się o uszy pojęcia takie jak model gwiazdy czy płatka śniegu Kimballa? Przez lata panowie ulepszali swoje pomysły i polemizowali, które podejście jest lepsze. W 2000 roku pojawił się nowy człowiek na scenie hurtownianej – Dan Linstedt ze swoim pomysłem nazwanym Data Vault. A tak naprawdę głośno zaczęło być o Data Vaultcie w roku 2013, gdy ogłoszono wersję 2.0.
Po co nowa koncepcja? Otóż Dan kładł nacisk na budowanie hurtowni z naciskiem na audyt oraz śledzenie danych ładowanych z wielu źródeł. Dodatkowo stawiał nacisk na elastyczność, skalowalność oraz jedną wersję prawdy.
Jeżeli chcesz poczytać więcej o koncepcji Data Vault, to nieskromnie polecę „trylogię”, której jestem współautorem:
O samych hurtowniach pisano książki, więc nie sposób temat wyczerpać w jednym akapicie. Mam nadzieję jednak, że po zgłębieniu tematu da Ci to poczucie, po co i jak hurtownie budujemy.
Czy warto uczyć się tych modeli danych?
Skoro część tych modeli jest starszych ode mnie, to pojawia się pytanie, czy warto się tego uczyć? Nie zawsze musimy uczyć się rzeczy od samego początku ich powstawania. Przykładowo nie widzę potrzeby walczenia ze wskaźnikami w języku C (tylko dlatego, żeby uczyć się od podstaw), aby później przejść do języka, w którym dzieje się to automatycznie. No, chyba że jest konkretna potrzeba użycia tego, a nie innego języka.
W przypadku różnych podejść i modeli danych jednak warto się z nimi zapoznać, bo są wciąż w powszechnym użytku. Kto wie, może zobaczymy coraz częstszą ich implementacje w świecie chmur. Ale o tym za chwilę 🙂

Przyszły czasy, w których zechcieliśmy przetwarzać dane, których było dużo i trudno było je objąć w ramy ustrukturyzowanego modelu. W odpowiedzi na to pojawiły się koncepcje:
Big Data oraz Data Lake
W momencie pojawienia się tych pojęć napotkaliśmy bardzo dużo niejasności. I tak, duży excel to nie Big Data, a Data Lake to nie śmietnik na dane. Na to mamy osobne pojęcie: Data Swamp 🙂
Big Data oraz Data Lake to nie są tożsame pojęcia. Pierwsze odnosi się do całego ekosystemu rozwiązań umożliwiających ogarnięcie danych opisanych za pomocą słynnych 3-6V (w zależności od punktu widzenia):
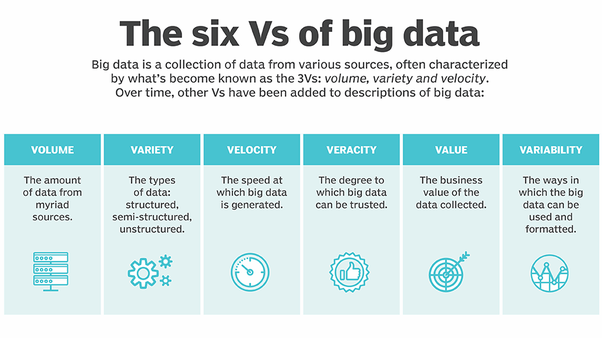
Sam Data Lake odnosi się do repozytorium danych, gdzie dane spełniające powyższe V-ki, zwłaszcza pierwsze trzy, mogą być przechowywane.
Nośnikiem takiego repozytorium mogą być Google Cloud Storage, HDFS (na Hadoopie), Amazon S3 czy Azure Storage. Zobacz jak przechowywać różne typy danych.
Schema-on-Read vs. Schema-on-Write
No dobra, możemy przechowywać różne dane, ale z czym się to wiąże? Otóż jedną z zasadniczych różnic między podejściem do tworzenia hurtowni danych i Data Lake jest moment, w którym zastanawiamy się nad modelem. Pojawiają się tutaj dwa nowe pojęcia: Schema-on-Read oraz Schema-on-Write.
Nietrudno się domyślić, że tradycyjne podejście do tworzenia hurtowni danych bazuje na metodzie Schema-on-Write. W tym podejściu najpierw modelujemy dane, a następnie zasilamy hurtownię. Oczywiście, to jak wygląda nasz schemat jest (a przynajmniej powinno być) przedmiotem analizy procesów, danych i tego, co chcemy osiągnąć.
W podejściu Schema-on-Read dla odmiany, o tym jak te dane będą ustrukturyzowane decydujemy podczas ich pobrania. Czy to do dalszej obróbki, czy prezentacji. Do tego czasu leżą sobie spokojnie w stanie niemalże nienaruszonym zanurzone w jeziorze danych.
Ma to swoje konsekwencje. Niekiedy niestety przykre, które są wynikiem podejścia: mam dane, nie wiem co z nimi zrobię, ale może się przydadzą. Trochę wygląda to jak takie natrętne zbieractwo 🙂
Pamiętaj, takie podejście nie powinno zwalniać nas z zastanowienia nad tym co i jak przechowujemy. Brak walidacji w postaci ustalonego modelu lub potrzeby zastanowienia się nad jego rozszerzeniem powoduje, że robi się nam śmietnik.

To jest trochę jak ze… skarpetkami. Możemy po praniu ich nie parować. Zaoszczędzimy trochę czasu, ale później będziemy tę decyzję przeklinać, szukając odpowiedniej kiedy akurat wyjątkowo się śpieszymy. Zwłaszcza kiedy trzymamy je jeszcze w różnych szufladach i/lub pomieszane z innymi częściami garderoby*.
*nie dotyczy: pracy zdalnej/osób, które mają tylko takie same skarpetki lub zawsze noszą dwie inne 🙂
Mając taką elastyczność co do możliwości przechowywania różnych typów danych, pojawiła się potrzeba (jak nigdy wcześniej) odpowiedniego podejścia do danych. W tym ich katalogowania i opisywania, aby panować nad tym, co mamy w naszym repozytorium.
Całość prowadzi nas do następnego podejścia:
Lakehouse
Pojęcie Lakehouse zostało zaprezentowane przez firmę Databricks w artykułe: What is a Lakehouse? Artykuł jest esencją z dokumentu badawczego: Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores.
Całość uzasadnia istnienie produktu tej firmy: The Databricks Lakehouse Platform 🙂 Nie mam doświadczenia z tym narzędziem, ale warto przyjrzeć się samej koncepcji.
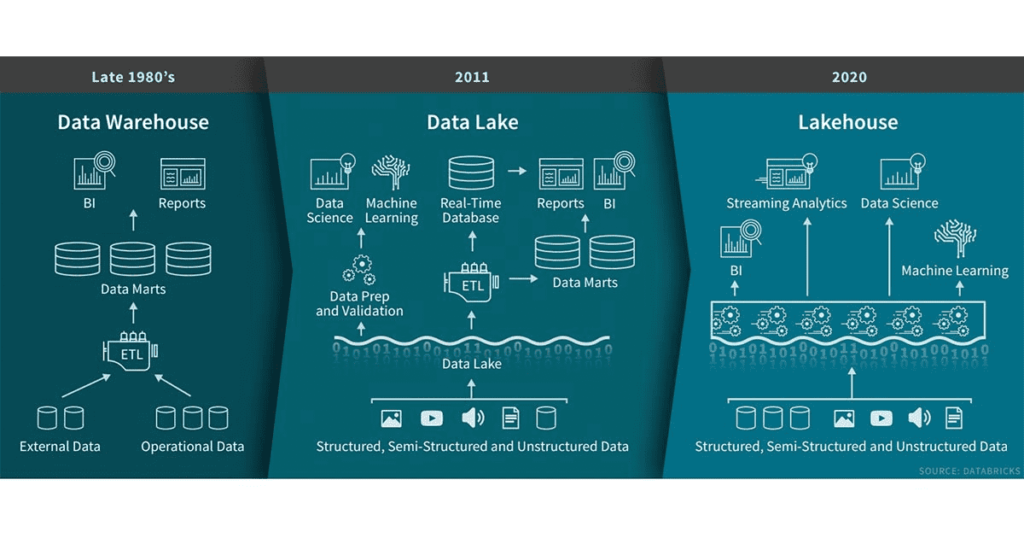
Czym jest ten domek nad jeziorem? W założeniu bierze najlepsze rzeczy z dwóch podejść i łączy je ze sobą. Za artykułem: jest to użycie podobnych struktur i elementów zarządzania danych w klasycznym podejściu, z relatywnie tanią przestrzenią danych używaną w Data Lake.
Dostajemy m.in.:
- wsparcie dla transakcji (ACID),
- możliwości tworzenia i utrzymania modelu danych i jego rozwoju (wraz ze wsparcie klasycznych modeli gwiazdy i płatka śniegu),
- dostęp do danych przez API, czyli możemy używać tych danych w innych narzędziach (w tym wsparcie dla SQLa),
- wsparcie dla danych nieustrukturyzowanych,
- wsparcie dla danych strumieniowych.
Hurtownię możemy wyobrazić sobie jako taki magazyn, gdzie mamy wszystko poukładane na półkach, na których znajdujemy dopasowane do nich rzeczy. W jeziorze z kolei mamy głębię, w której może kryć się dużo różnych rzeczy (w tym potwory!). Ten domek nad jeziorem to jest próba ustrukturyzowania tego co mamy w jeziorze.
Modern Cloud Data Warehouse
Kolejnym artykułem, na który chciałbym zwrócić Twoją uwagę, jest tekst opisujący Data Lake jako stan przejściowy pomiędzy klasyczną hurtowną a nowoczesną hurtownią budowaną w chmurze (Modern Cloud Data Warehouse): Data Lakes Are Legacy Tech, Fivetran CEO Says.
Fraser (wspomniany CEO firmy Fivetran) wskazuje, że repozytoria danych zyskały ogromną popularność poprzez relatywnie niski koszt przechowywania danych, w porównaniu do tradycyjnych hurtowni.

Jak mówi, ta przewaga zanika. Duża separacje przestrzeni dyskowej od mocy obliczeniowej wraz z możliwościami, jakie nam dają chmury, powoduje, że ten aspekt nie ma już takiej mocy. Jednocześnie wzrastają możliwości skalowania nowoczesnych hurtowni opartych o chmurę.
Popularności tej opinii nadaje wejście na amerykańską giełdę firmy Snowflake i to, co się stało z jej wyceną zaraz po IPO (ang. Initial Public Offering). Platforma do danych o tej samej nazwie stała się produktem kojarzonym z nowoczesnym podejściem do hurtowni danych. Jednocześnie umożliwia wykorzystanie Data Lake jako jedno ze źródeł danych.

Źródło: https://docs.snowflake.com/en/user-guide/intro-key-concepts.html
I to ostatnie podejście znajduje coraz więcej zwolenników. Niekoniecznie repozytoria danych znikną, ale przestaną być centralnym punktem. Staną się częścią składową (źródłem danych) większego ekosystemu.
Tutaj mamy do czynienia z tzw. federated approach. Nie mamy jednego centralnego repozytorium. Tworzymy rozwiązanie, które korzysta z wielu źródeł, stając się punktem wejściowym do zdecentralizowanych danych. Dane odpytujemy za pomocą tzw. federated queries. Takie możliwości dają również rozwiązania takie jest Dremio lub Presto.
Oczywiście w omawianych przypadkach mamy do czynienia z argumentami, które mają wzmocnić konkretne produkty. Niemniej jednak sama koncepcje i trend wydaje się być ciekawy.
Dodatkowo, w każdym przypadku pojawia się SQL! Widzisz, mówiłem, że SQL to język angielski świata IT! A jeżeli chcesz się nauczyć jak analizować dane przy pomocy SQLa to – jak to mówią – stay tuned 🙂
Podsumowanie
Mam nadzieję, że omówione koncepcje Cię zainteresowały. Ciekawostką jest to, że historia może zatoczyć koło. Modele, które były używane w latach 90-tych mogą wrócić w nowej odsłonie, na scenie chmurowej. Czy tak będzie? Nie wiem, ale pojawiają się takie pomysły.
Pamiętaj, że budowanie systemu to nie tylko wybór modelu przechowywania danych czy technologii. Tutaj w grę wchodzą dodatkowe elementy takie jak Data Governance. Jest to kluczowe w dzisiejszym świecie – zwłaszcza w kontekście regulacji, którą muszą spełnić np. instytucje finansowe.
Jestem przekonany, że coraz częściej będą potrzebni specjaliści, którzy wiedzą jak radzić sobie z danymi i mają wachlarz możliwości. Tacy jak inżynierowie danych. Natomiast widzę mniejsze zapotrzebowanie na „wymiataczy” od jednej konkretnej technologii. Oczywiście Ci ostatni nie znikną, ale będzie ich potrzeba relatywnie mniej. To tylko moja opinia. Czy tak będzie, pokaże czas 🙂
