

W ostatnim wpisie serii Od Zera Do Bohatera omówiliśmy sobie jak podejść do tworzenia systemów przetwarzania danych. Wspomniałem tam, że przybliżę Ci różne źródła danych.
W tym wpisie skupmy się na plikach, bo bardzo często korzysta się z nich przy dostarczaniu danych, a wielokrotnie napotykałem przeróżne problemy z plikami, w których dostarczane są dane. Zarówno takie, które powodowały błędy podczas procesowania danych, jak po prostu schemat dostarczony wraz z plikami, kompletnie nie pomagał, aby dane zrozumieć.
Wyobraź sobie, że mamy taki diagram (model logiczny), który ma na celu zobrazować dane, które przetwarzamy:
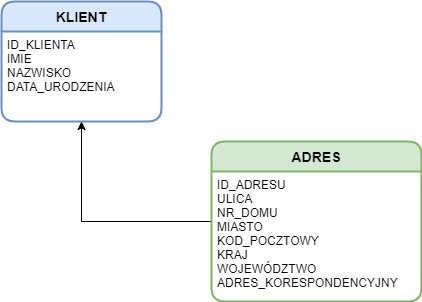
Wynika z niego, że mamy tabelę KLIENT, która przechowuje klientów z ich podstawowymi danymi i tabelę ADRES, która przechowuje adresy. Nie chciałbym wchodzić w analizę danych relacyjnych, ale na potrzeby tych przykładów zwróćmy uwagę, że jeden klient może mieć wiele adresów, a jeden adres w systemie może być przypisane jedynie do danego klienta. Nawet gdy mamy dwóch klientów pod tym samym adresem (np. małżeństwo), to adres występuje dwa razy i jest przypisany do dwóch różnych klientów.