

W ostatnim wpisie serii Od Zera Do Bohatera omówiliśmy sobie jak podejść do tworzenia systemów przetwarzania danych. Wspomniałem tam, że przybliżę Ci różne źródła danych.
W tym wpisie skupmy się na plikach, bo bardzo często korzysta się z nich przy dostarczaniu danych, a wielokrotnie napotykałem przeróżne problemy z plikami, w których dostarczane są dane. Zarówno takie, które powodowały błędy podczas procesowania danych, jak po prostu schemat dostarczony wraz z plikami, kompletnie nie pomagał, aby dane zrozumieć.
Wyobraź sobie, że mamy taki diagram (model logiczny), który ma na celu zobrazować dane, które przetwarzamy:
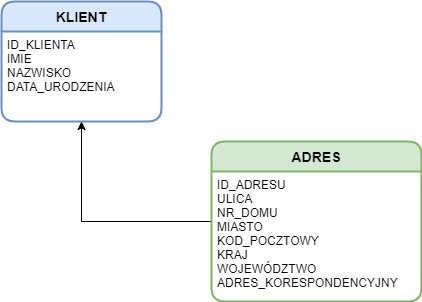
Wynika z niego, że mamy tabelę KLIENT, która przechowuje klientów z ich podstawowymi danymi i tabelę ADRES, która przechowuje adresy. Nie chciałbym wchodzić w analizę danych relacyjnych, ale na potrzeby tych przykładów zwróćmy uwagę, że jeden klient może mieć wiele adresów, a jeden adres w systemie może być przypisane jedynie do danego klienta. Nawet gdy mamy dwóch klientów pod tym samym adresem (np. małżeństwo), to adres występuje dwa razy i jest przypisany do dwóch różnych klientów.
Przykładowe dane mogą wyglądać tak (to jest jedynie przykład, więc nie przykładaj tutaj wagi czy dane mają sens biznesowy):
| KLIENT | |||
|---|---|---|---|
| ID_KLIENTA | IMIE | NAZWISKO | DATA_URODZENIA |
| 1 | Maciej | Przykładowy | 1980-03-05 |
| 2 | Aleksandra | Zmyślna | 1987-09-09 |
| 3 | Waldemar | Wspaniały | 1977-08-08 |
| 4 | Zofia | Wilańska | 1988-03-30 |
| ADRES | ||||||||
|---|---|---|---|---|---|---|---|---|
| ID_ADRESU | ID_KLIENTA | ULICA | NR_DOMU | MIASTO | KOD_POCZTOWY | KRAJ | WOJEWÓDZTWO | ADRES_KORESPONDENCYJNY |
| 1 | 3 | Wygodna | 3 | Warszawa | 04-633 | Polska | mazowieckie | T |
| 2 | 2 | Błotna | 16 | Katowice | 40-008 | Polska | śląskie | N |
| 3 | 1 | Szamarzewskiego | 2 | Poznań | 61-004 | Polska | wielkopolskie | N |
| 4 | 1 | Kościelna | 10 | Poznań | 60-539 | Polska | wielkopolskie | T |
| 5 | 2 | Zachlapana | 2 | Katowice | 40-100 | Polska | śląskie | T |
| 6 | 4 | Diamentowa | 33 | Elbląg | 82-300 | Polska | warmińsko-mazurskie | T |
| 7 | 4 | Fromborska | 13 | Elbląg | 82-317 | Polska | warmińsko-mazurskie | N |
Kolorami zaznaczyłem identyfikatory, które łączą się ze sobą. Te diagramy służą do zobrazowania danych, które z kolei zapiszemy później w plikach (tych, które możemy odczytywać).
Zwróć uwagę, że tabela ADRES zawiera kolumnę: ID_KLIENTA. Jest to powiązanie między tabelami. Co nam mówi ta kolumna? Mówi to nam tyle: ten konkretny adres (ADRES.ID_ADRESU) jest przypisany do klienta o identyfikatorze ADRES.ID_KLIENTA. Fizycznie to połączenie jest realizowane poprzez odniesienie od ADRES.ID_KLIENTA do KLIENT.ID_KLIENTA.
Krótka dygresja. Zauważyłes(-aś), że na pierwszym diagramie brakuje pola ADRES.ID_KLIENTA? Nie jest to błąd. Pole ID_KLIENTA odnosi się do klienta, a po stronie adresu stanowi „jedynie” powiązanie. W modelach logicznych często takich powiązań się nie prezentuje. Umieszcza się na nich jedynie atrybuty przynależące biznesowo do danej encji. Dodatkowo często pomijamy identyfikatory stanowiące klucz podstawowy jeżeli są kluczami sztucznymi (czego w tym przypadku celowo nie zrobiłem, aby nie zaciemniać obrazu). Natomiast całość (uwzględniając techniczne atrybuty) jest uwzględniana w modelach fizycznych.
Przejdźmy teraz do prezentacji tych danych przy pomocy różnych plików.
1. CSV (ang. Comma-Separated Values)
Zacznijmy od CSV, który jest najprostszym typem pliku przechowującego danych. Przechowuje dane w sposób „płaski”. Jeżeli chcielibyśmy wyeksportować dane z naszych tabel i zapisać w pliku CSV, to mamy 2 opcje:
- Zapisane danych w dwóch osobnych plikach
- Zapisanie danych w jednym pliku już połączonych
Jeżeli wyeksportujemy dane do osobnych plików to będzie to wyglądać tak:
ID_KLIENTA,IMIE,NAZWISKO,DATA_URODZENIA
1,Maciej,Przykładowy,1980-03-05
2,Aleksandra,Zmyślna,1987-09-09
3,Waldemar,Wspaniały,1977-08-08
4,Zofia,Wilańska,1988-03-30ID_ADRESU,ID_KLIENTA,ULICA,NR_DOMU,MIASTO,KOD_POCZTOWY,KRAJ,WOJEWÓDZTWO,ADRES_KORESPONDENCYJNY
1,3,Wygodna,3,Warszawa,04-633,Polska,mazowieckie,T
2,2,Błotna,16,Katowice,40-008,Polska,śląskie,N
3,1,Szamarzewskiego,2,Poznań,61-004,Polska,wielkopolskie,N
4,1,Kościelna,10,Poznań,60-539,Polska,wielkopolskie,T
5,2,Zachlapana,2,Katowice,40-100,Polska,śląskie,T
6,4,Diamentowa,33,Elbląg,82-300,Polska,warmińsko-mazurskie,T
7,4,Fromborska,13,Elbląg,82-317,Polska,warmińsko-mazurskie,NNatomiast jak całość wrzucimy do jednego, to będziemy mieli wynik, w którym rekordy z dwóch plików zostaną połączone (bazując na ID_KLIENTA):
ID_KLIENTA,IMIE,NAZWISKO,DATA_URODZENIA,ID_ADRESU,ULICA,NR_DOMU,MIASTO,KOD_POCZTOWY,KRAJ,WOJEWÓDZTWO,ADRES_KORESPONDENCYJNY
1,Maciej,Przykładowy,1980-03-05,3,Szamarzewskiego,2,Poznań,61-004,Polska,wielkopolskie,N
1,Maciej,Przykładowy,1980-03-05,4,Kościelna,10,Poznań,60-539,Polska,wielkopolskie,T
2,Aleksandra,Zmyślna,1987-09-09,2,Błotna,16,Katowice,40-008,Polska,śląskie,N
2,Aleksandra,Zmyślna,1987-09-09,5,Zachlapana,2,Katowice,40-100,Polska,śląskie,T
3,Waldemar,Wspaniały,1977-08-08,1,Wygodna,3,Warszawa,04-633,Polska,mazowieckie,T
4,Zofia,Wilańska,1988-03-30,6,Diamentowa,33,Elbląg,82-300,Polska,warmińsko-mazurskie,T
4,Zofia,Wilańska,1988-03-30,7,Fromborska,13,Elbląg,82-317,Polska,warmińsko-mazurskie,NKtóre rozwiązanie jest lepsze? Klasyczna odpowiedź – to zależy. Oczywistym problemem w drugim przypadku są powtórzenia wartości. Wpływa to na czytelność, ale także „wagę” pliku. Natomiast, jeżeli chcemy mieć całość w jednym miejscu i załadować to do hurtowni, która obsługuje powtórzenie danych (np. BigQuery na GCP), to warto, żeby to był jeden plik.
W przypadku plików osobnych albo ładujemy je do osobnych encji, albo jesteśmy sami odpowiedzialni za ich „sklejenie” podczas procesowania. W naszym przypadku, bazując na polu ID_KLIENTA. Nie ma jednej dobrej odpowiedzi 🙂
Ten typ pliku nazywa się w wolnym tłumaczeniu: „oddzielony przecinkiem”. Nie musi tak być. Sami możemy zdefiniować separator, tak długo jak będzie to czytelne dla naszych odbiorców. Możemy również spotkać rozszerzenie dedykowane dla plików rozdzielonych tabulacją: TSV (ang. Tab-Separated Values).
Pamiętaj, aby separator nie znalazł się w naszych danych jeżeli nie używamy cudzysłowu. Aby to zademonstrować, dodałem do naszego przykładu kolumnę KOMENTARZ, gdzie dodałem testowe wartości. Przykład przygotowałem w Google Sheet i wyeksportowałem do pliku CSV. Narzędzie automatycznie dodało cudzysłów, ale tylko w miejscach, gdzie występuje separator:
ID_KLIENTA,IMIE,NAZWISKO,DATA_URODZENIA,KOMENTARZ
1,Maciej,Przykładowy,1980-03-05,"To jest testowa wartość, która zawiera przecinek"
2,Aleksandra,Zmyślna,1987-09-09,Ta wartość nie zawiera przecinka
3,Waldemar,Wspaniały,1977-08-08,
4,Zofia,Wilańska,1988-03-30,"A tutaj mamy więcej przecinków, bo aż dwa, prawda?"Jeżeli chodzi o plusy CSV, to:
- prostota,
- czytelny dla człowieka,
- łatwy w implementacji,
- zrozumiany przez większość narzędzi,
- „lekki” (oprócz danych nie przechowujemy żadnych innych informacji).
Z minusów, podkreśliłbym:
- płaska struktura,
- problematyczna prezentacja danych relacyjnych,
- brak możliwości określenia schematu,
- brak rozróżnienia braku pola od wartości null,
- rośnie waga pliku jeżeli trzymamy dane relacyjne w jednym pliku.
Na część tych minusów, znajdziemy odpowiedź poniżej.
2. XML (ang. Extensible Markup Language)
XML (w wolnym tłumaczeniu zwany rozszerzalnym językiem znaczników) jest typem plików, w którym (w przeciwieństwie do plików CSV), możemy budować struktury. Powyższy przykład mógłby zostać zaprezentowany jak poniżej:
<?xml version="1.0" encoding="utf-8"?>
<daneKlientow>
<klient>
<idKlienta>1</idKlienta>
<imie>Maciej</imie>
<nazwisko>Przykładowy</nazwisko>
<dataUrodzenia>1980-03-05</dataUrodzenia>
<adres>
<idAdresu>3</idAdresu>
<ulica>Szamarzewskiego</ulica>
<nrDomu>2</nrDomu>
<miasto>Poznań</miasto>
<kodPocztowy>61-004</kodPocztowy>
<kraj>Polska</kraj>
<wojewodztwo>wielkopolskie</wojewodztwo>
<adresKorespondencyjny>N</adresKorespondencyjny>
</adres>
<adres>
<idAdresu>4</idAdresu>
<ulica>Kościelna</ulica>
<nrDomu>10</nrDomu>
<miasto>Poznań</miasto>
<kodPocztowy>60-539</kodPocztowy>
<kraj>Polska</kraj>
<wojewodztwo>wielkopolskie</wojewodztwo>
<adresKorespondencyjny>T</adresKorespondencyjny>
</adres>
</klient>
<klient>
<idKlienta>2</idKlienta>
<imie>Aleksandra</imie>
<nazwisko>Zmyśna</nazwisko>
<dataUrodzenia>1987-09-09</dataUrodzenia>
<adres>
<idAdresu>2</idAdresu>
<ulica>Błotna</ulica>
<nrDomu>16</nrDomu>
<miasto>Katowice</miasto>
<kodPocztowy>40-008</kodPocztowy>
<kraj>Polska</kraj>
<wojewodztwo>śląskie</wojewodztwo>
<adresKorespondencyjny>N</adresKorespondencyjny>
</adres>
<adres>
<idAdresu>5</idAdresu>
<ulica>Zachlapana</ulica>
<nrDomu>2</nrDomu>
<miasto>Katowice</miasto>
<kodPocztowy>40-100</kodPocztowy>
<kraj>Polska</kraj>
<wojewodztwo>śląskie</wojewodztwo>
<adresKorespondencyjny>T</adresKorespondencyjny>
</adres>
</klient>
<klient>
<idKlienta>3</idKlienta>
<imie>Waldemar</imie>
<nazwisko>Wspaniały</nazwisko>
<dataUrodzenia>1977-08-08</dataUrodzenia>
<adres>
<idAdresu>1</idAdresu>
<ulica>Wygodna</ulica>
<nrDomu>3</nrDomu>
<miasto>Warszawa</miasto>
<kodPocztowy>04-633</kodPocztowy>
<kraj>Polska</kraj>
<wojewodztwo>mazowieckie</wojewodztwo>
<adresKorespondencyjny>T</adresKorespondencyjny>
</adres>
</klient>
<klient>
<idKlienta>4</idKlienta>
<imie>Zofia</imie>
<nazwisko>Wilańska</nazwisko>
<dataUrodzenia>1988-03-30</dataUrodzenia>
<adres>
<idAdresu>6</idAdresu>
<ulica>Diametowa</ulica>
<nrDomu>33</nrDomu>
<miasto>Elbląg</miasto>
<kodPocztowy>82-300</kodPocztowy>
<kraj>Polska</kraj>
<wojewodztwo>warmińsko-mazurskie</wojewodztwo>
<adresKorespondencyjny>T</adresKorespondencyjny>
</adres>
<adres>
<idAdresu>7</idAdresu>
<ulica>Fromborska</ulica>
<nrDomu>13</nrDomu>
<miasto>Elbląg</miasto>
<kodPocztowy>820317</kodPocztowy>
<kraj>Polska</kraj>
<wojewodztwo>warmińsko-mazurskie</wojewodztwo>
<adresKorespondencyjny>N</adresKorespondencyjny>
</adres>
</klient>
</daneKlientow>Ustrukturyzowana forma jest zdecydowanie zaletą. Wynika z niej, który klient ma jakie adresy. Nie ma także potrzeby powielania danych klientów dla każdego adresu.
Oczywiście tutaj są również pewne znaki, które musimy odpowiednio oznaczyć. Spójrz jeszcze raz na strukturę i zastanów się jakie potencjalne znaki mogą powodować, że plik XML nie będzie poprawnie interpretowany?
Na pewno problematyczne będą znaki, których używamy do tworzenia znaczników, np. <idKlienta>. Jeżeli chcesz użyć w wartości pola znaku: > lub < to musisz je zamienić odpowiednio na > (greater than) lub < (less than). Tak naprawdę jedynie problemyczny jest znak mniejszy niż, bo to on otwiera znacznik, ale dobrze zamieniać również ten drugi. Kolejnym, częstym przykładem jest ampersand (&). Jeżeli np. w polu nazwy firmy występuje ampersand to musisz zamienić go na &. Przykładowo: Arek&Spółka zapiszemy:
<nazwaFirmy>Arek&Spółka</nazwaFirmy>
Więcej informacji znajdziesz na stronie W3Schools.
Problem ze znakami specjalnymi jest dość częstym problemem przy przetwarzaniu danych poprzez pliki XML, także zwróć proszę na to uwagę.
Dodatkową zaletą XMLa w porównaniu do CSV jest to, że można stworzyć schemat, czyli taki szablon jak te dane powinny wyglądać. Robi się to za pomocą np. pliku XML Schema, czyli XSD. Plik dla naszego przykładu mógłby wyglądać tak:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="daneKlientow">
<xs:complexType>
<xs:sequence>
<xs:element name="klient" maxOccurs="unbounded" minOccurs="1">
<xs:complexType>
<xs:sequence>
<xs:element type="xs:integer" name="idKlienta"/>
<xs:element type="xs:string" name="imie"/>
<xs:element type="xs:string" name="nazwisko"/>
<xs:element type="xs:date" name="dataUrodzenia"/>
<xs:element name="adres" maxOccurs="unbounded" minOccurs="1">
<xs:complexType>
<xs:sequence>
<xs:element type="xs:integer" name="idAdresu"/>
<xs:element type="xs:string" name="ulica"/>
<xs:element type="xs:string" name="nrDomu"/>
<xs:element type="xs:string" name="miasto"/>
<xs:element type="xs:string" name="kodPocztowy"/>
<xs:element type="xs:string" name="kraj"/>
<xs:element type="xs:string" name="wojewodztwo"/>
<xs:element type="xs:string" name="adresKorespondencyjny"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>Ten plik możemy użyć do weryfikacji czy dane, które dostaliśmy, są zgodne ze schematem. Jest to bardzo istotne, ponieważ pozwala nam zweryfikować czy to, co otrzymaliśmy jest tym czego oczekiwaliśmy 🙂
Zauważ, że oprócz typu string mamy także typ opisujący datę (date) oraz liczby całkowite (integer).
To nie jest pełny opis XMLa, bo jest to dość obszerny temat. Pełną listę typów, oraz dodatkowe tematy takie jak przestrzenie nazwy czy atrybuty możesz poznać zaglądać na stronę W3Schools.
Podsumowując, na plus tego typu pliku zaliczyłbym głównie:
- czytelność,
- powszechność,
- możliwość zaprezentowania bardziej skomplikowanych struktur (relacji, zagnieżdżeń itp.),
- przestrzenie nazw,
- wsparcie dla wartości null,
- możliwość walidacji.
Minusem XML głównie jest:
- „waga” plików (każdy atrybut jest wymieniony 2 razy jak tag rozpoczynający i zamykający),
- brak natywnego wsparcia dla tablic (ang. arrays).
XML może być używany nie tylko do przenoszenia danych batchowych. Jest często używane do wysyłania wiadomości pomiędzy różnymi usługami lub aplikacjami.
W zasadzie powinienem napisać, że był używany do celów opisanych powyżej. Dlaczego? Otóż wydaje się, że w większości przypadków został zastąpiony plikiem typu JSON.
3. JSON (ang. JavaScript Object Notation)
Jak sama nazwa wskazuje, plik ten się wywodzi z języka JavaScript, ale dzisiaj jest używany powszechnie.
Nasze dane w JSONonie by wyglądały tak:
{
"daneKlientow": {
"klient": [
{
"idKlienta": 1,
"imie": "Maciej",
"nazwisko": "Przykładowy",
"dataUrodzenia": "1980-03-05",
"adres": [
{
"idAdresu": 3,
"ulica": "Szamarzewskiego",
"nrDomu": "2",
"miasto": "Poznań",
"kodPocztowy": "61-004",
"kraj": "Polska",
"wojewodztwo": "wielkopolskie",
"adresKorespondencyjny": "N"
},
{
"idAdresu": 4,
"ulica": "Kościelna",
"nrDomu": "10",
"miasto": "Poznań",
"kodPocztowy": "60-539",
"kraj": "Polska",
"wojewodztwo": "wielkopolskie",
"adresKorespondencyjny": "T"
}
]
},
{
"idKlienta": 2,
"imie": "Aleksandra",
"nazwisko": "Zmyśna",
"dataUrodzenia": "1987-09-09",
"adres": [
{
"idAdresu": 2,
"ulica": "Błotna",
"nrDomu": "16",
"miasto": "Katowice",
"kodPocztowy": "40-008",
"kraj": "Polska",
"wojewodztwo": "śląskie",
"adresKorespondencyjny": "N"
},
{
"idAdresu": 5,
"ulica": "Zachlapana",
"nrDomu": "2",
"miasto": "Katowice",
"kodPocztowy": "40-100",
"kraj": "Polska",
"wojewodztwo": "śląskie",
"adresKorespondencyjny": "T"
}
]
},
{
"idKlienta": 3,
"imie": "Waldemar",
"nazwisko": "Wspaniały",
"dataUrodzenia": "1977-08-08",
"adres": {
"idAdresu": 1,
"ulica": "Wygodna",
"nrDomu": "3",
"miasto": "Warszawa",
"kodPocztowy": "04-633",
"kraj": "Polska",
"wojewodztwo": "mazowieckie",
"adresKorespondencyjny": "T"
}
},
{
"idKlienta": 4,
"imie": "Zofia",
"nazwisko": "Wilańska",
"dataUrodzenia": "1988-03-30",
"adres": [
{
"idAdresu": 6,
"ulica": "Diametowa",
"nrDomu": "33",
"miasto": "Elbląg",
"kodPocztowy": "82-300",
"kraj": "Polska",
"wojewodztwo": "warmińsko-mazurskie",
"adresKorespondencyjny": "T"
},
{
"idAdresu": 7,
"ulica": "Fromborska",
"nrDomu": "13",
"miasto": "Elbląg",
"kodPocztowy": "820317",
"kraj": "Polska",
"wojewodztwo": "warmińsko-mazurskie",
"adresKorespondencyjny": "N"
}
]
}
]
}
}Weźmy na tapetę mniejszy fragment i przeanalizujmy dokładniej. Poniższy fragment nie jest poprawnym JSON, a jedynie wyciętym kawałkiem powyższego przykładu (w linii nr 32 znajdziesz trzy kropki):

Nazwy pól są przekazywane w cudzysłowie oddzielone dwukropkiem od wartości. Te z kolei mogą być różnego typu. Jeżeli jest to typ liczbowy (number), to wartości nie są ujęte w cudzysłów, w przeciwieństwo do łańcucha znaków (string). Wszystkie wspierane typy możesz znaleźć tutaj.
Kolejne pola odseparowane są od siebie przecinkami. Całe obiekty są okalane klamrami, np. klient wraz z adresami (linia 4 oraz 31). Również same zagnieżdżone obiekty są otoczone tak samo, np. wystąpienia adresów (linia 10 i 19; 20 i 29). Dodatkowo pojawia się nawias kwadratowy (linia 9), który wskazuje, że obiekty w nim się znajdujące są tablicą (ang. arrays), czyli mogą występować wielokrotnie. Tak jak w przypadku naszego adresu. Oczywiście nawias ten musi zostać zamknięty (linia 30). Podobnie pozostałe klamry i nawiasy. Cały dokument również jest objęty w klamry.
Wracają na chwilę do tablic (ang. arrays), to w JSONie możemy zapisać tablicę, która będzie zawierała nie tylko obiekty, ale po prostu wartości np.:
"kolory":["czerwony","zielony","niebieski","pomarańczowy","łosoś to ryba, a nie kolor:)"]Chociaż ja odróżniam jedynie 16 kolorów (i to już z podziałem na jasne i ciemne), to nie znalazłem żadnego ograniczenia na liczbę elementów w takiej tablicy 🙂
Tak samo jak w przypadku XMLa, w JSONie też możemy natrafić na znaki specjalne. Przykładowo – cudzysłów, który używany jest do wartości znakowych. Jeżeli chcemy mieć cudzysłów w wartościach, to musimy to jawnie wskazać w pliku poprzez użycie: \”
{
"opis": "to jest pole zawierające tytuł filmu: \"Fajny film\""
}Dla JSONa można również utworzyć schemat i zwalidować, czy dostarczony plik jest poprawny. Schemat dla naszego przykładu mógłby wyglądać tak:
{
"type":"object",
"required":[
],
"properties":{
"daneKlientow":{
"type":"object",
"required":[
],
"properties":{
"klient":{
"type":"array",
"items":{
"type":"object",
"required":[
],
"properties":{
"idKlienta":{
"type":"number"
},
"imie":{
"type":"string"
},
"nazwisko":{
"type":"string"
},
"dataUrodzenia":{
"type":"string"
},
"adres":{
"type":"array",
"items":{
"type":"object",
"required":[
],
"properties":{
"idAdresu":{
"type":"number"
},
"ulica":{
"type":"string"
},
"nrDomu":{
"type":"string"
},
"miasto":{
"type":"string"
},
"kodPocztowy":{
"type":"string"
},
"kraj":{
"type":"string"
},
"wojewodztwo":{
"type":"string"
},
"adresKorespondencyjny":{
"type":"string"
}
}
}
}
}
}
}
}
}
}
}W sieci jest sporo różnych generatorów i walidatorów. Przykładowy znajdziesz tutaj. O samym schemacie (ang. JSON Schema) więcej możesz przeczytać tutaj.
Warto wspomnieć, że JSON jest również często używany jako forma reprezentowania wiadomości (ang. messages) w różnego rodzaju narzędziach, np. Cloud Pub/Sub na GCP.
Podsumowując, na plus JSONa:
- czytelność,
- powszechność,
- możliwość zaprezentowania bardziej skomplikowanych struktur,
- możliwość walidacji,
- wsparcie dla tablic,
- wsparcie dla wartości null,
- plik jest „lżejszy” (mniej zajmuje miejsca) w porównaniu z XMLem
To, co może w tym typie przeszkadzać to fakt, że natywnie nie wspiera przestrzeni nazw.
Teraz omówimy dwa przykłady plików binarnych. Zasadnicza różnica pomiędzy plikiem binarnym a tekstowym jest taka, że tych pierwszych nie przeczytasz bez odpowiedniego narzędzia. To dlaczego w ogólnie z nich korzystać?
Krótko można odpowiedzieć, że są wydajniejsze, zwłaszcza przy składowaniu i przetwarzaniu „dużych danych”.
Podstawową różnicą pomiędzy plikami binarnymi jest to, jak zapisywane są w nich dane: wierszowo lub kolumnowo.
Spójrzmy jeszcze raz na nasz przykład:
| KLIENT | |||
|---|---|---|---|
| ID_KLIENTA | IMIE | NAZWISKO | DATA_URODZENIA |
| 1 | Maciej | Przykładowy | 1980-03-05 |
| 2 | Aleksandra | Zmyślna | 1987-09-09 |
| 3 | Waldemar | Wspaniały | 1977-08-08 |
| 4 | Zofia | Wilańska | 1988-03-30 |
Dane przechowywane są w blokach (ang. blocks). I teraz mamy dwie opcje stworzenia takiego bloku:
- [1, „Maciej”, „Przykładowy”,1980-03-05…] – zapis rekordowy
- [„Maciej”,”Aleksanda”,”Waldemar”,”Zofia”] – zapis kolumnowy
Oczywiście bloki mogą trzymać więcej niż jeden wiersz oraz kolumnę. Warto to rozumieć, ponieważ zapis wierszowy lub kolumnowy pojawia się także w kontekście baz danych. Przejdźmy do omówienia pierwszego pliku.
4. Avro
Avro jest otwartym (ang. open-source) typem stworzonym przez Apache. Jego cechą charakterystyczną jest to, że jest zapisany wierszowo, przez co lepiej radzi sobie z dodawaniem danych. Wyobraź sobie, jak zapisujemy sobie naszych klientów. Wiersz po wierszu. Zdecydowanie łatwiej dodać jest kolejny wierszy na końcu pliku/bloku niż w rozbiciu na poszczególne kolumny.
Kolejną cechą tego typu pliku jest to, że oprócz danych dostarczany w formie binarnej, ich schemat zapisywanie jest postaci JSONa i trzymany wraz z danymi. Dzięki temu, narzędzie, które wczytuje dane, może bardzo łatwo rozpoznać, jaka jest ich struktura.
5. Parquet
Parquet jest również darmowym, otwartym (ang. open-source) typem pliku. Jego podstawową różnicą w porównaniu z Avro, jest zapis kolumnowy. Odczyt danych jest bardzo szybki, ale głównie gdy potrzebujemy danych z konkretnych kolumn.
Dodatkowo (podobnie jak w przypadku kolumnowych baz danych) znacznie lepiej sprawdza się w analizach, gdzie musimy dane agregować bazując na konkretnych kolumnach. Taki sposób przetrzymywania danych jest również efektywny pod kątem kompresji pliku.
Parquet jest zoptylizowany do pojedynczego zapisu i wielokrotnego odczytu. Jak to w IT już bywa, mamy na to konkretny skrót – WORM (ang. Write Once Read Many). Wynika to z tego, że zapis trwa stosunkowo wolno (w przeciwieństwo do odczytu). Może to być minus w przypadkach, gdy dane muszą być często aktualizowane.
Innym przykładem kolumnowego typu pliku jest ORC (ang. Optimized Row Columnar). Różni się od Parqueta, ale tutaj musielibyśmy wejść w detale, które oczywiście mają znaczenie, ale nie chciałbym zaciemniać obrazu. Nie znalazłem na tyle różnic, aby omawiać go osobno, ale warto mieć świadomość jego istnienia 🙂 Co można pokreślić, to, że z różnych benchmarków wynika, że ORC można jeszcze lepiej skompresować.
Podsumowanie
Omówiliśmy podstawowe typy plików, które ułatwią Ci pracę z danymi. Wynika to z powszechności używania tego typu plików. Kiedyś XML, dzisiaj JSON, są podstawowym typem pliku wymiany informacji pomiędzy aplikacjami i serwisami. Nie tylko w systemach skupionych na danych. Również JSON „obsługuje” różne interfejsy, np. REST API.
Dodatkowo, pliki są często używane przy przenoszeniu danych z jednego miejsca do drugiego, nawet jeżeli dane te wcześniej leżą w bazie danych. Dlaczego używamy plików? Np. nie chcemy dać nikomu dostępu do naszej bazy danych.
Do tego dochodzą pliki binarne (nieczytelne dla człowieka). W nich również możemy przechowywać dane, a następnie je importować do dowolnego narzędzia obsługującego dany typ. Który z nich wybrać? Klasycznie – to zależy od potrzeb i narzędzia. Przykładowo, BigQuery preferuje Avro jako format danych, które chcemy załadować, ale obsługuje także inne, również tekstowe.
Pamiętaj, że jeżeli pracujesz na potężnych zbiorach danych, to musisz przeanalizować jaki typ pliku będzie dla Ciebie najbardziej odpowiedni. W takich przypadkach nie ma jednoznacznej odpowiedzi.
Słowo na dziś z ITmowy

Jest to rodzaj zadania, w którym skupiamy się na rozwiązaniu technicznym, które pozwoli nam później zbudować funkcjonalności biznesowe
Jest to często używane w świecie Agile. Przykładem takiego enablera może być przygotowanie jakiegoś kawałka architektury, frameworka, biblioteki, która w dalszej części projektu przyspieszy dostarczanie funkcjonalności.

super blog. Napisany z poziomem szczegółowości na tyle dużym żeby rozjaśniał zasadnicze kwestie i różnice między różnymi technologiami, i na tyle umiarkowanym, żeby nie przytłaczał czytelnika zbytnimi detalami.
Cześć Adamie,
dziękuję za komentarz. Bardzo się cieszę, że tak odbierasz mojej wpisy. Dokładnie taki mam cel – pisać przystępnym językiem o rzeczach (niekiedy) trudnych, ale jednocześnie ciekawych! 🙂
Pozdrawiam!