

Dane ustrukturyzowane czy nie? Relacyjne czy nie? Duże lub małe? Silna spójność w danych (ang. strong consistency) czy ostateczna (ang. eventual consistency)?
Sporo tego, prawda? W tym artykule rozwieję trochę wątpliwości. Myślę, że jak to omówimy, to w połączeniu z rozumieniem typów plików (przybliżonych w poprzednim wpisie), będzie Ci łatwiej poruszać się w świecie przetwarzania danych.
Temat różnych typów danych poruszyłem już we wpisie omawiających 7 pytań, które musisz zadać, projektując system przetwarzający dane. Jeżeli go nie znasz, to mocno zachęcam, aby spojrzeć na niego w pierwszej kolejności. Dzisiejszy artykuł jest jego rozwinięciem.
Z racji, że aktualnie najbardziej na czasie są technologie chmurowe, a mi z kolei najbliżej do Google Cloud Platform, to na tym rozwiązaniu się głównie skupimy, od strony narzędziowo-praktycznej. Większość z wymienionych tu usług odwiedzimy jeszcze osobno, aby dokładniej się im przyjrzeć, ale teraz chciałbym Ci te rozwiązania przedstawić z „lotu ptaka”. Umożliwi Ci to poznanie możliwości, które mamy w naszej palecie.
Jakie dane możemy napotkać?
Powiedzieliśmy sobie w wymienionym wpisie, że dane dzielimy na ustrukturyzowane (ang. structured) oraz nieustrukturyzowane (ang. unstructured). Często pojawiają się jeszcze dane częściowo ustrukturyzowane (ang. semi-structred), do których zaliczamy rozwiązania NoSQL. Czasem dane typu NoSQL są zaliczanie do danych nieustrukturyzowanych, natomiast ja zaliczyłem je do tych pierwszych, ze względu, że jednak można je opisać schematem. Podobny podział znajdziemy w artykule na cloud.google.com:
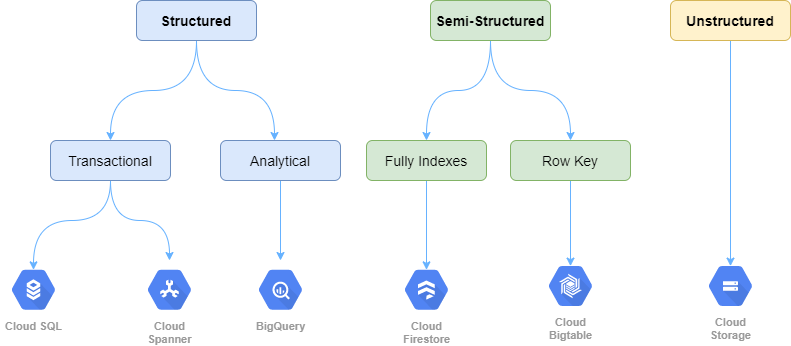
Na rysunku widzimy dane ustrukturyzowane, które dzielą się na transakcyjne oraz analityczne; częściowo ustrukturyzowane, które są tak naprawdę danymi NoSQL. Ostatnią kategorią są dane nieustrukturyzowane, czyli wszystko inne.
Dane ustrukturyzowane
Mówiąc o danych ustrukturyzowanych bardzo często mamy na myśli dane relacyjne. Te z kolei możemy podzielić na modele OLTP (ang. Online Transaction Processing) oraz OLAP (ang. Online Analytical Processing). Te dwa pojęcia wyjaśniłem we wspomnianym wpisie, odpowiadając na pytanie: „Projektujesz system transakcyjny czy analityczny?” – zajrzyj tam po więcej informacji.
Z punktu widzenia modelowania tych danych warto wspomnieć o normalizacji. Cechą systemów transakcyjnych jest to, że są one znormalizowane, czyli zamodelowane w taki sposób, aby uniknąć niespójności w danych oraz ich redundancji (powielania).
Opis procesu normalizacji znajdziesz w artykule autorstwa mojego kolegi, Kuby Kasprzaka, pt.: Projektowanie i normalizacja bazy danych. Zbieżność nazwisk zupełnie przypadkowa 🙂
O ile świadoma denormalizacja może występować także w systemach OLTP, to powszechnie stosuje się ją w modelach analitycznych, typu OLAP. Modele te są często używane w hurtowniach danych. Nazywamy je często modelami wymiarowymi (ang. dimentional models). Układamy w nich dane tak, aby łatwo było wykonywać operacje takie jak:
- agregowanie danych,
- wgłębianie się w dane – od ogółu do szczegółu (ang. drilling down),
- przeglądanie danych pod wieloma wymiarami (np. czas, struktura organizacyjna…).
Takie struktury mogą być implementowane w relacyjnych bazach danych lub też w wyspecjalizowanych rozwiązaniach wielowymiarowych (ang. multidimentional).
Od strony narzędziowej, dostępnych rozwiązań dla przechowywania danych strukturalnych/relacyjnych mamy mnóstwo. Wszytko zależy od scenariusza, ale możemy zaryzykować stwierdzenie, że do pewnego poziomu skomplikowania, większość relacyjnych baz danych się nadaje.
Jeżeli chodzi o GCP, to tutaj do rozwiązań transakcyjnych wykorzystujemy usługę Cloud SQL lub Cloud Spanner. Cloud SQL jest w pełni zarządzaną usługą (ang. fully managed) bazy danych opartą na znanych już rozwiązaniach. Do wyboru mamy: MySQL, PostreSQL lub SQL Server. Usługa ta jest dedykowana do zbiorów danych o wielkości maksymalnej 30 TB danych. Dodatkowo jest regionalna, czyli całość trzymana jest w jednym regionie.
Jeżeli te pojęcia nie są dla Ciebie jasne, to zapraszam do ściągnięcia darmowego dokumentu, w którym wyjaśniam 22 zagadnienia, które pozwolą Ci zacząć pracę z chmurami:

Cloud Spanner jest usługą stworzoną i w pełni zarządzaną przez Google. Cloud SQL możemy skalować jedynie wertykalnie (poprzez dodanie zasobów do instancji; alternatywnie stworzenie dodatkowej repliki tylko do odczytu). Cloud Spanner natomiast może być skalowany horyzontalnie (możemy dodawać kolejne maszyny). Spanner jest rozwiązaniem globalnym, czyli możemy mieć węzły w kilku regionach. Zaznaczyć trzeba, że nawet w takim przypadku, wciąż mamy do czynienia ze silną spójnością danych (ang. strong consistency). Znaczy to tyle, że dane, w każdym momencie odczytujemy najświeższe dane (w przeciwieństwie do ostatecznej spójności, ale o tym za chwilę).
Usługa ta jest dedykowana do bardziej wymagających scenariuszy, przez to jest znacznie droższa. Jak chcesz zobaczyć ile dana usługa będzie Cię kosztować to zerknij na kalkulator na GCP.
Jeżeli chodzi o dane analityczne, to tutaj mamy do czynienia ze szlagierowym produktem Googla czyli BigQuery.
Jest to serverlessowa hurtownia danych, która potrafi operować na petabajtach danych. Wspiera (a nawet promuje) dane zdenormalizowane. Potrafi ładować dane z różnych plików: CSV, JSON, Avro czy Parquet. Dane fizycznie przechowywane są kolumnowo, więc zoptymalizowane są pod zapytania analityczne. Co ciekawe, można na niej uruchamiać również modele Machine Learningowe. Jest to jedno z tych rozwiązań, któremu jeszcze poświęcimy więcej czasu w niedalekiej przyszłości.
Zanim przejdziemy do danych NoSQL, to warto zastanowić się, czy to są jedyne dostępne rozwiązania w chmurze GCP? Oczywiście nie. Zarówno w chmurze Google jak i innych dostawców, istnieje możliwość uruchomienia maszyny wirtualnej, a na niej zainstalowania prawie każdej bazy danych. Prawie, ponieważ są dystrybucje, które niechętnie na to pozwalają, jak np. Oracle. Możemy uruchomić Oracle’a na GCP, ale tutaj musimy korzystać z dedykowanej maszyny. Niestety często wynika to z ograniczeń licencyjnych. Pozostaje pytanie – czy ma to sens jeżeli możemy korzystać z gotowych usług.
Przejdźmy teraz do omówienia danych NoSQL.
Dane częściowo ustrukturyzowane
Co tak naprawdę rozumiemy pod tym pojęciem? Powszechnie uważa się, że znaczy to dokładnie to, jak się to czyta, czyli „no SQL” albo „non-relational”. Znalazłem inne rozwinięcie tego skrótu, znacznie lepiej oddające dzisiejsze użycie tych narzędzi – „Not Only SQL„.
Mówimy tutaj o 4 typach baz danych:
- Klucz-wartość (Key value store) – gdzie klucz identyfikuje dany obiekt,
- Dokumentowa (Document store) – możemy zapisać tam pliki typu JSON,
- Kolumnowa (Column family) – baza kolumnowa,
- Grafowa (Graph store) – zoptymalizowana pod zapisywanie grafów.
Dla zobrazowania przywołajmy jeszcze raz grafikę ze wspomnianego wpisu:

Zanim przejdziemy do omawiania konkretnych rozwiązań, wróćmy na chwilę do wspomnianej wyżej ostatecznej spójności (ang. eventual consistency). Co to znaczny, że nasze dane ostatecznie są spójne? W praktyce wygląda to tak, że jeżeli mamy replikację w klastrze, to istnieje punkt w czasie, gdy nasze zmiany nie zostaną spropagowane na wszystkie węzły. Jeżeli w tym czasie odpytamy konkretny węzeł o dane, to możemy otrzymać ich nieaktualną wersję.
Przy dzisiejszych rozwiązaniach nie możemy powiedzieć, że rozwiązania NoSQL nie udostępniają silnej spójności. Często poziomami spójności możemy sterować w różnych narzędziach. Ale jak to bywa – nie ma nic za darmo. Jeżeli chcemy zawsze mieć silną spójność danych, może odbywać się to kosztem wydajności. Jak skupimy się na konkretnych rozwiązaniach, to opowiemy sobie bardziej szczegółowo, jakie mamy możliwości. Na teraz warto zapamiętać, że musimy dokładnie rozumieć nasze wymagania, aby wybrać odpowiednie rozwiązanie. Nie tylko pod kątem SQL vs. NoSQL, ale również wchodzą w grę mechanizmy replikacji, spójność danych itp.
Baza key-value
Bazy danych klucz-wartość cechuje to, że z tym kluczem (key) mamy skojarzone „jakieś” dane (value). Dlaczego jakieś? Bo tak naprawdę struktura tych danych może się różnić w każdym rekordzie. Może to być łańcuch znaków, kolekcja albo dokument JSON. W przypadku tego ostatniego pamiętaj, że nie możesz go przeszukiwać. Możesz go jedynie pobrać, podając odpowiedni, przypisany do niego klucz.

W GCP mamy usługę Memorystore, której jednym ze wcieleń jest baza Redis – opensource’owa baza in-memory (trzymająca dane w pamięci głównej) typu klucz-wartość. Co prawda na stronie Redisa znajdziecie inną nazwę: in-memory data structure store, a to dlatego, że chcą podkreślić, że tymi przetrzymywanymi wartościami mogą być różne struktury:

Nie odczytuj powyższej grafiki tak, że jedna wartość klucza może wskazywać na wiele rekordów. Grafika ma na celu zaprezentować mnogość struktur mogących być przechowywanych w polu wartość. Bazy te sprawdzają się bardzo dobrze do buforowania (cachowania) wartości, przechowywania różnego rodzaju konfiguracji czy profili. Wszędzie tam, gdzie zależy nam na szybkości zapisu i odczytu. Nie sprawdzą się natomiast tam, gdzie musimy budować różnego rodzaju relacje pomiędzy danymi.
Baza dokumentowa
Baza dokumentowa jest to rodzaj przestrzeni, w której możemy składować dokumenty np. jako struktury JSON czy też XML. Najpopularniejszy jest jednak ten pierwszy typ. Przykładową bazą dokumentową jest MongoDB. Na poniższej grafice znajdziesz odzwierciedlenie relacyjnego modelu w formę „dokumentową” przechowywaną w bazie:

W przypadku GCP mamy do dyspozycji rozwiązanie Firestore, które jest następcą usługi Datastore i może też działać w trybie kompatybilnym ze swoim poprzednikiem. W przeciwieństwie do baz typu key-value, w bazie dokumentów, po odpowiednim zaindeksowaniu pól możemy wyszukiwać dane w samych dokumentach.
Bazy te świetnie sprawdzają się w systemach typu e-commerce, CRM czy też wszędzie tam, gdzie przechowujemy struktury typu JSON.
Jeżeli natomiast musimy zapewnić silną spójność, wsparcie dla transakcji i dodatkowo relacyjność danych, to bazy dokumentowe mogą nie być najlepszym wyborem.
Column family
Bazy kolumnowe możemy rozumieć jako sposób przechowywania danych (ang. column store) i tutaj nie musimy mówić tylko o bazach NoSQL. Przykładem może być wspomniana baza BigQuery. Nie jest to baza typu column family, a jednak dane fizycznie składowane są kolumnowo, co jest optymalne pod kątem agregowania danych.
Jeżeli chodzi nam o układ kolumnowy w rozumieniu logicznej organizacji danych, to przykładową tabelę możemy zaprezentować następująco:

Taką familię (ang. column family) możemy rozumieć trochę jak tabelę w relacyjnej bazie danych.
Brak sztywnej struktury powoduje, że gdy nie ma wartości dla danej kolumny, to nie alokujemy dla niej żadnego miejsca. Przez co zużycie przestrzeni dyskowej jest znacznie mniejsze. Często takie rozwiązania określamy mianem sparse (rzadkie).
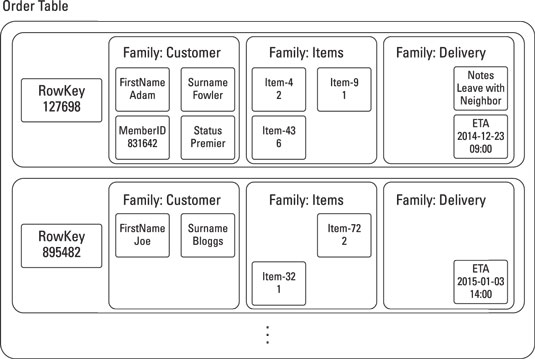
Przykładem takiego rozwiązania jest baza Cassandra. W przypadku GCP rozwiązaniem jest Bigtable, czyli wide–column stores, które może przechowywać do 100 column families i miliony kolumn. Jest co prawda niezwykle wydajnym rozwiązaniem (Google sam z tego korzysta), ale niestety stosunkowo drogim.
Tego typu rozwiązanie świetnie nadaje się do dużych ilości danych, gdzie wymagamy bardzo mały opóźnień, odczytujemy dane po kluczu. Dodatkowo mamy ograniczoną paletę różnych zapytań, czyli wiemy jak one wyglądają, a przez to możemy odpowiednio zaprojektować klucz (row key), którego używamy. W przypadku Bigtable jest to krytyczne, aby unikać zjawiska zwanego hotspotting, czyli nadmiernego używania jednego węzła. Powodem tego może być źle zaprojektowany klucz, co skutkuje nierównomiernym rozłożeniem obciążenia na węzły w klastrze. Inaczej mówiąc dane, o które najczęściej pytamy, leżą na jednym węźle.
Takie rozwiązanie idealnie nadaje się to składowania danych typu time-series, odczytów z urządzeń IoT czy aplikacji, gdzie mamy przeważającą liczbę zapisów nad odczytami.
Rozwiązane to nie nadaje się do systemów OLTP lub OLAP.
Bazy grafowe
Ostatnim typem baz danych, o którym chciałbym wspomnieć, jest baza grafowa. Wykorzystujemy ją gdy chcemy zaprezentować obiekty (węzły grafu) oraz relacje pomiędzy nimi (połączenia).
Przykładem takiego grafu może być sieć społecznościowa, gdzie węzłami są dane osoby, a linkami relacje (powiązania) między nimi:

Google nie ma swojej bazy grafowej. AWS z kolei oferuje bazę AWS Neptune a według dokumentacji Azure posiada model grafowy w swojej bazie Azure CosmosDB. Abstrahując od chmur, to jednym z najpopularniejszych rozwiązań na rynku jest Neo4J.
Takiej bazy możemy użyć wszędzie tam, gdzie mamy potrzebę przeszukania powiązań pomiędzy obiektami. Takimi powiązaniami mogą być relacje pomiędzy podmiotami gospodarczymi albo reprezentacja transakcji między nimi (np. w celu wychwycenia nadużyć). Również w taki sposób możemy zaprezentować aktywność na jakimś portalu:
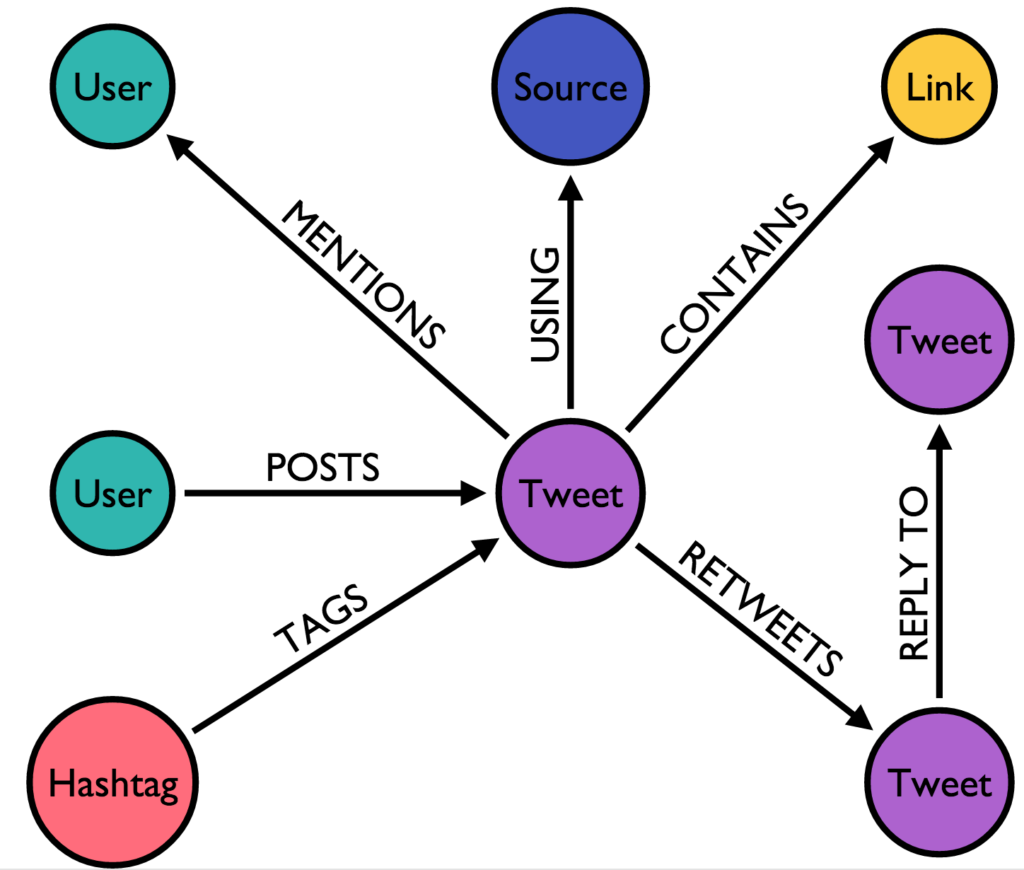
Naturalnie taka baza nie jest dobrym rozwiązaniem jeżeli nie mamy potrzeby wykonywać zaawansowanych analiz, opartych o właściwości opisane powyżej.
Dane nieustrukturyzowane
Z danymi nieustrukturyzowanymi jest jednocześnie łatwo i trudno. Łatwo je zdefiniowować – jako wszystko inne 🙂 Trudniej natomiast sobie z nimi poradzić.
Próbujemy to robić budując różne rodzaju rozwiązania typu Data Lake. Jeżeli chodzi o przechowywanie tych danych, to tak naprawdę potrzebujemy miejsca, gdzie przechowamy różnego rodzaju pliki, np. dysk, Google Cloud Storage, HDFS (na Hadoopie), Amazon S3 czy Azure Storage.
W tym przypadku przechowywanie nie stanowi większego wyzwania. Te zaczynają się gdy chcemy te dane przetwarzać i wyciągać z nich wartościowe informacje 🙂
Podsumowanie
Mam nadzieję, że po przeczytaniu tego artykułu, lepiej będziesz orientować się w możliwościach przechowywania różnych danych.
Trochę tego dużo i zastanawiasz się co wybrać? Myślę, że pomoże Ci poniższy diagram:
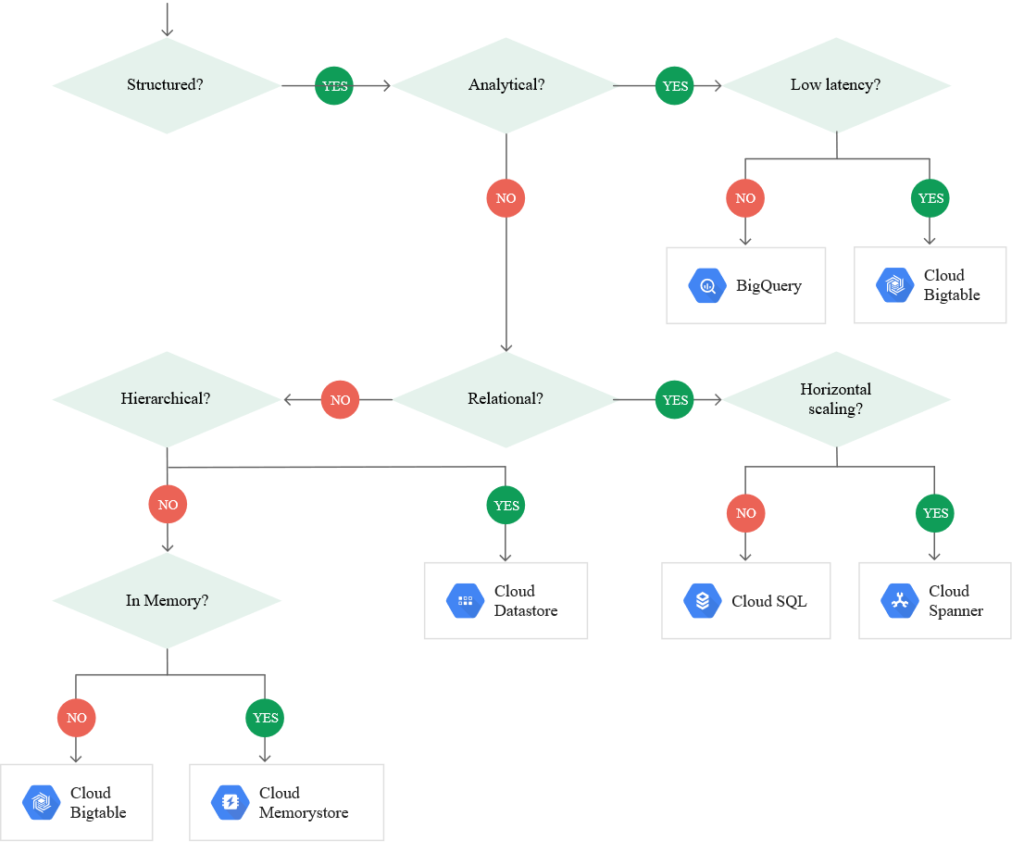
Z usługami chmurowymi zapoznamy się bliżej już wkrótce, również od strony praktycznej, więc zapraszam do śledzenia bloga.
Słowo na dziś z ITmowy

Skrót SDLC, czyli Software Development Life Cycle, używany jest bardzo często w świecie IT. Opisuje cykl życia oprogramowania składający się z kilku etapów, np.: analiza, projektowanie, implementacja, testowanie, uruchomienie i utrzymanie wraz z rozwojem.

Witam, link do pobrania pliku ’22 zagadnienia do pracy…’ nie działa. 🙂
Cześć Arturze!
Dzięki za komentarz. Link już powinien działać.
Pozdrawiam
Arek