

W poprzednich artykułach z serii Od Zera Do Bohatera omówiłem różnego rodzaju pliki, z którymi możesz się spotkać oraz sposoby przechowywania danych nie tylko ustrukturyzowanych. W ostatnim z kolei opowiedzieliśmy sobie o nowoczesnych podejściach do projektowania systemu opartego o dane.
Do pełnego (wysokopoziomowego) obrazu brakuje nam jeszcze elementu odpowiadającego za przerzucanie danych z jednego miejsca do drugiego. I tu pojawiają się dwa podejścia – ETL vs. ELT.
Te idee nie są szczególnie nowe i już kiedyś o nich pisałem:
Powyższy tekst ma już kilka lat, ale zerknij do niego jeżeli jesteś ciekaw, jak te dwa podejścia można zastosować w samych relacyjnych bazach danych.
Ten artykuł traktuję jako wersję 2.0. Temat odświeżam tak, aby uwzględnić kontekst chmurowy. Ale zacznijmy pokrótce od podstaw.
Czym jest ETL?
Proces ETL w uproszczeniu składa się z 3 kroków:
- Extract – wyładowanie danych ze źródeł i zasilenie przestani tymczasowej
- Transform – krok, w którym następuje przeprocesowanie danych włącznie z ich uzgadnianiem, czyszczeniem, poprawianiem
- Load – załadowanie danymi do miejsca docelowego
Nie chciałbym skupiać się na wyjaśnieniu całego procesu ETL, ponieważ temat ten jest na tyle obszerny, że powstało mnóstwo publikacji dogłębnie opisujących zagadnienie.
W skrócie, w ujęciu bardzo klasycznym można to zaprezentować w taki oto sposób:
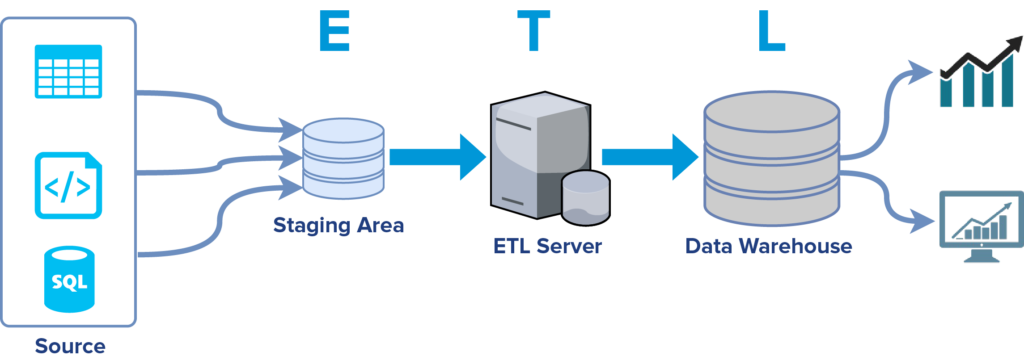
Pobieramy dane z systemów źródłowych i składujemy je w przestrzeni tymczasowej (Extract). Następnie – często za pomocą dodatkowego oprogramowania i infrastruktury – przetwarzamy te dane tak, aby pasowały do naszej hurtowni (Transform). W końcowym etapie dane ładujemy do DWH (Load).
Oczywiście w świecie chmur, nie musimy mieć dedykowanego „blaszaka” z oprogramowaniem ETL. Możemy do tego używać rozwiązań chmurowych, ale dalej idea jest taka sama. Najpierw wyładowujemy dane, obrabiamy je (czyścimy, walidujemy itp.) i ładujemy do docelowego miejsca.
I tu pojawia się problem. Skoro chcemy przechowywać mnóstwo różnorodnych danych, to przetwarzanie ich zaraz po wyładowaniu i transformowanie do docelowego (z góry ustalonego) schematu nie wydaje się zawsze optymalne. Okazuje się, że może tutaj pomóc – tylko i aż – zamiana liter ETL -> ELT 🙂
ETL vs. ELT
Czy jak z samej nazwy wynika, ELT jest jedynie odwróceniem kolejności kroków procesowania – najpierw Load, a później Transform? Nie, a raczej – nie tylko.
Podejście, w którym decydujemy się w ostatnim kroku transformować dane, jest konsekwencją budowania całego procesu. Często proces ELT definiuje się tak, że ładowanie i transformacja następują w miejscu docelowym:
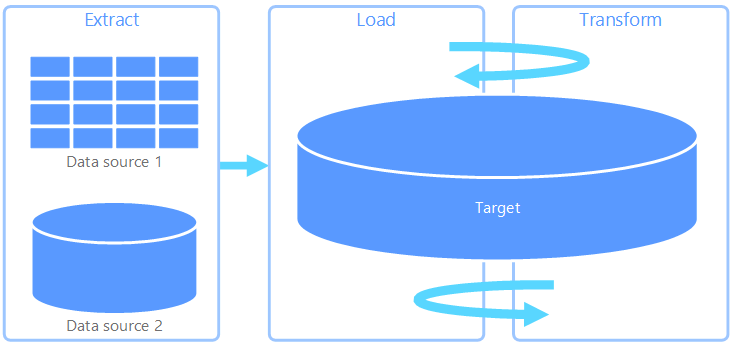
Dodatkowo wiążę się to z pojęciami, o których pisałem w ostatnim tekście: Schema-On-Read vs. Schema-On-Write, czyli kiedy decydujemy, jak ma wyglądać nasz docelowy model.
Jeżeli budujemy tradycyjną hurtownię danych, to mamy z góry ustalony schemat, a więc transformacja danych zachodzi przed ich załadowaniem. Często używamy do tego dodatkowych narzędzi ETL (wraz z infrastrukturą), takich jak: Informatica, SSIS, Pentaho, InfoSphere Data Stage, Ab Initio.
Niemniej jednak w tradycyjnym ujęciu również można korzystać z procesu ELT. Dane wyładowujemy z obszaru tymczasowego oraz ładujemy i transformujemy w docelowej hurtowni.

Przykładowe Case Study zaprezentowałem w artykule: ETL vs. ELT, czyli różne podejścia do zasilenia hurtowni i repozytoriów danych.
Ale idźmy dalej. Wyobraźmy sobie, że planujemy zbudować nasze repozytorium danych w oparciu Data Lake, gdzie trzymamy wyekstrahowane z systemów źródłych surowe dane. Następnie te dane są źródłem w dalszym procesowaniu. Jakim? Dowolnym. Może to być budowanie nowoczesnej hurtowni danych. Może to być źródło do zasilenia modeli Machine Learningowych lub też przetransformowanie ich do postaci zrozumiałej przez kolejny system (ang. upstream system).

Istotne jest, że w każdym z tych przypadków, końcowa transformacja następuje na ostatnim etapie, w ostatnim elemencie. Do tego czasu dane leżą w formacie względnie surowym.
Oczywiście taki proces możemy rozpatrywać zarówno w skali mikro jak i makro. Fakt, że pewien mikro proces ETL/ELT się wykonał, to nie znaczy, że to końcowa podróż dla danych. W momencie gdy jeden proces się kończy, inny może się zacząć (np. pobierać dane do innego systemu, do dalszego procesowania).
A jak to wygląda w chmurach?
Sam pomysł na ELT powstał dawno i był już używany w klasycznych hurtowniach danych. Natomiast popularność zaczął zyskiwać w momencie pojawienia się Data Lake i ekosystemu związanego z przetwarzaniem Big Data. Jednak dopiero coraz szersza adopcja chmur w przetwarzaniu danych rozsławiła go niczym Oczy zielone – Zenka Martyniuka 🙂
Popularność zyskuje model opisany w poprzedniej sekcji. Dane surowe zebrane ze źródeł leżą sobie w miejscu umożliwiającym składowanie danych ustrukturyzowanych oraz nie. I z tego miejsca są ładowane i transformowane zgodnie z zapotrzebowaniem. Tak jak wspomniałem wyżej, w chmurach również mamy możliwość przetwarzania danych w modelu ETL.
Proces przetwarzania danych w chmurze może być nieco bardziej skomplikowany i zawierać więcej kroków niż trzy wymienione powyżej. Również możemy mieć więcej mikro procesów ETL/ELT. Samo przesunięcie i transformacja danych mogą być również wykonane na wiele sposobów. Przykładowo, na GCP możemy użyć dedykowanego narzędzia ETL/ELT, np. Data Fusion, ale również możemy taki proces oprogramować w Dataflow czy też używając funkcji w Cloud Functions.
Czy w Data Lake zawsze mamy „surówki”?
Tutaj warto posłużyć się najczęściej używanym określeniem w IT: „to zależy”. Dygresja: chyba od czasów pracy zdalnej, jednak najczęściej używanym jest „you are on mute” 🙂
Odpowiadając na pytanie – nie. Moim zdaniem nie zawsze. Potrafię sobie wyobrazić przypadki, w których dane lądujące w Data Lake muszę przejść jakąś transformacje. Przykładem takiej transformacji może być anomizacja lub pseudoanonimzacja danych wrażliwych, używając takich technik jak maskowanie czy tokenizacja.
Podsumowanie
Przerzucanie danych pomiędzy różnymi częściami ekosystemu spaja cały proces. To czy wybieramy jedno podejście, czy inne nie jest (a przynajmniej nie powinno) być zależne od naszych preferencji tylko tego, jakie mamy wymagania co do danych oraz naszego rozwiązania.
Nie ma jednoznacznej odpowiedzi, który proces jest lepszy. Każdy ma swoje zastosowanie. Niemniej jednak podejście ELT jest coraz bardziej popularne. Dzięki swojej elastyczności lepiej odpowiada na wymagania stawiane obecnym systemom przetwarzania danych. Zwłaszcza dzisiaj, w świecie technologii chmurowych, gdzie dane surowe mogą leżeć w Data Lake, a hurtownie możemy budować jako kolejny krok przetwarzania. Jeżeli popełnimy błąd, to nic nie stoi na przeszkodzie, aby hurtownie usunąć i stworzyć na nowo z poprawną transformacją. A może stworzymy drugą w innej usłudze? Możliwości są duże 🙂
Słowo na dziś z ITmowy

Feedy, w rozumieniu Data feeds, czyli dostarczanie danych z jednego systemu do innego.
Możemy tego użyć w mowie w formie: mamy nowe feedy do zonboardowania. To ostatnie słowo to kolejna dziwna konstrukcja językowa, którą wyjaśnię w następnym artykule.

Dziękuję – bardzo ciekawy artykuł 🙂
U nas ze względów czysto kosztowych w większości projektów optymalniej kosztowo zrobić transformację za pomocą DataForm właśnie zakładając warstwową architekturę hurtowni w BigQuery.
Więc w większości przypadków chętniej sięgamy po ELT vs ETL , ale nie rzadko się to spotyka z opozycją po stronie klienta, który przyzwyczaił się do innej kolejności tego procesu 🙂
Dodam tylko, że to na tyle malutkie projekty, że w warstwie produkcyjnej 1 TB wystarczy na procesy transformacyjne co powoduje, że są darmowe:)
Nie bez znaczenia jest też kwestia kompetencji analityków i inżynierów u klienta. Czy bliżej im do zrozumienia SQLX czy raczej Python jest ich codziennym narzędziem pracy.
Cześć Arkady!
Dziękuję za komentarz.
Pozdrawiam!